Table of Contents
In this notebook, you will learn:
- What is AutoEncoder?
- What is Variational AutoEncoder?
- Understanding latent space and encoder/decoder network
- Implementing VAE in PyTorch
What is AutoEncoder?
AutoEncoder has been fully explained in the previous notebook, So let’s review:
An autoencoder is a type of neural network that learns to encode input data into a lower-dimensional representation and then decodes the representation back to its original form. The goal of an autoencoder is to learn a compressed representation of the input data while minimizing the reconstruction error between the original data and its reconstructed version.
The architecture of an autoencoder typically consists of an encoder network that maps the input data to a lower-dimensional representation, and a decoder network that maps the representation back to the original data space. The encoder and decoder networks are trained jointly using backpropagation to minimize the reconstruction error.
Autoencoders can be used for various tasks such as dimensionality reduction, feature extraction, and data denoising. One example of using autoencoders for dimensionality reduction is in image compression, where the encoder network compresses the high-dimensional image data into a lower-dimensional code, and the decoder network reconstructs the image from this code.
Another application of autoencoders is in anomaly detection, where the model is trained on normal data and then used to detect anomalies that deviate significantly from the learned distribution. Anomalies in the input data produce large errors in the reconstruction phase, making them easier to detect.

What is a VAE?
Variational Autoencoder (VAE) is a generative model that learns the underlying latent space of the input data. It is a type of neural network architecture that consists of an encoder and a decoder network. The encoder network maps the input data to its corresponding latent space representation, while the decoder network maps the latent space representation back to the original input data. VAEs are used for various applications including image and text generation, anomaly detection, and data compression.
The main idea behind VAEs is to learn a lower-dimensional representation of the input data that captures its salient features and can be used to generate new samples. This is achieved through an encoder-decoder architecture, where the encoder maps the input data into a latent space, and the decoder maps the latent space back to the original input.
However, unlike traditional autoencoders, VAEs also parameterize a probability distribution over the latent space, allowing them to sample new points from the learned distribution. The encoder learns to map the input data to a mean vector and a variance vector that define a Gaussian distribution over the latent space. During training, the loss function encourages the distribution learned by the encoder to match a pre-defined prior distribution, typically a unit Gaussian.
Once the model has been trained, it can be used to generate new samples by sampling from the learned distribution in the latent space and then decoding the resulting vector back to the original input space.

Understanding VAE
Latent Space
The goal of VAE is to learn the underlying distribution of the input data. This is achieved by mapping the input data to a lower-dimensional latent space where each point represents a unique feature of the input data. For example, if we have an image dataset, the latent space of the images would contain features like shape, texture, color, etc. The number of dimensions in the latent space is usually much less than the number of input dimensions, which helps in reducing the complexity of the model.
Encoder Network
The encoder network takes in the input data and maps it to a point in the latent space. The output of the encoder is not a single point, but rather a probability distribution over the latent space. This distribution is usually modeled as a Gaussian distribution with mean and variance vectors:
z_mean, z_log_var = encoder(x)
The z_mean vector represents the mean of the distribution, while z_log_var represents the log variance. We use log variance instead of variance to ensure that the variance is always positive. The mean and variance vectors are used to sample a point from the latent space as follows:
z = z_mean + exp(z_log_var / 2) * epsilon
where epsilon is a random noise vector sampled from a standard normal distribution N(0,1)
Decoder Network
The decoder network takes in a point from the latent space and maps it to the original input data. The output of the decoder is again a probability distribution over the input space, which is modeled as a Bernoulli distribution in the case of binary inputs or a Gaussian distribution in the case of continuous inputs:
x_mean = decoder(z)
The x_mean vector represents the mean of the distribution over the input space.
Loss Function
The loss function for VAE consists of two parts: the reconstruction loss and the KL divergence loss.
Reconstruction Loss
The reconstruction loss measures how well the decoder is able to reconstruct the original input given a point in the latent space. This loss is usually calculated as the binary cross-entropy loss in the case of binary inputs or the mean squared error loss in the case of continuous inputs:
reconstruction_loss = binary_cross_entropy(x, x_mean) # For binary inputs
reconstruction_loss = MSELoss(x, x_mean) # For continuous inputs
KL Divergence Loss
The KL divergence loss measures how closely the distribution over the latent space matches a standard normal distribution. This loss encourages the encoder to learn a distribution over the latent space that is close to a standard normal distribution, which helps in regularizing the model and avoiding overfitting. The KL divergence loss is given by:

Total Loss
The total loss is the sum of the reconstruction loss and the KL divergence loss:
total_loss = reconstruction_loss + kl_loss
Implementation using PyTorch
First, we need to import the necessary libraries:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
Next, we define the hyperparameters for the VAE:
latent_dim = 20
batch_size = 128
learning_rate = 1e-3
num_epochs = 30
num_samples = 16
latent_dim is the number of dimensions in the latent space, batch_size is the number of samples per batch, learning_rate is the learning rate for the optimizer, num_epochs is the number of epochs to train for, and num_samples is the number of samples to generate from the learned distribution.
We also need to define the transformations to be applied to the input images:
transformations = transforms.Compose([
transforms.ToTensor(),
])
These transformations convert the images to PyTorch tensors and normalize the pixel values to have 0 mean and 1 variance.
We will use the MNIST dataset for this example, which consists of grayscale images of handwritten digits. So, we load the MNIST dataset:
train_dataset = datasets.MNIST(root='./dataset', train=True, transform=transformations, download=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./dataset/MNIST/raw/train-images-idx3-ubyte.gz
100%|██████████| 9912422/9912422 [00:00<00:00, 332408903.88it/s]
Extracting ./dataset/MNIST/raw/train-images-idx3-ubyte.gz to ./dataset/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ./dataset/MNIST/raw/train-labels-idx1-ubyte.gz
100%|██████████| 28881/28881 [00:00<00:00, 56185386.75it/s]
Extracting ./dataset/MNIST/raw/train-labels-idx1-ubyte.gz to ./dataset/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ./dataset/MNIST/raw/t10k-images-idx3-ubyte.gz
100%|██████████| 1648877/1648877 [00:00<00:00, 144880934.25it/s]
Extracting ./dataset/MNIST/raw/t10k-images-idx3-ubyte.gz to ./dataset/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ./dataset/MNIST/raw/t10k-labels-idx1-ubyte.gz
100%|██████████| 4542/4542 [00:00<00:00, 21947613.79it/s]
Extracting ./dataset/MNIST/raw/t10k-labels-idx1-ubyte.gz to ./dataset/MNIST/raw
train_dataset[0]
(tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0118, 0.0706, 0.0706, 0.0706,
0.4941, 0.5333, 0.6863, 0.1020, 0.6510, 1.0000, 0.9686, 0.4980,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.1176, 0.1412, 0.3686, 0.6039, 0.6667, 0.9922, 0.9922, 0.9922,
0.9922, 0.9922, 0.8824, 0.6745, 0.9922, 0.9490, 0.7647, 0.2510,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1922,
0.9333, 0.9922, 0.9922, 0.9922, 0.9922, 0.9922, 0.9922, 0.9922,
0.9922, 0.9843, 0.3647, 0.3216, 0.3216, 0.2196, 0.1529, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0706,
0.8588, 0.9922, 0.9922, 0.9922, 0.9922, 0.9922, 0.7765, 0.7137,
0.9686, 0.9451, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.3137, 0.6118, 0.4196, 0.9922, 0.9922, 0.8039, 0.0431, 0.0000,
0.1686, 0.6039, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0549, 0.0039, 0.6039, 0.9922, 0.3529, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.5451, 0.9922, 0.7451, 0.0078, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0431, 0.7451, 0.9922, 0.2745, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.1373, 0.9451, 0.8824, 0.6275,
0.4235, 0.0039, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.3176, 0.9412, 0.9922,
0.9922, 0.4667, 0.0980, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1765, 0.7294,
0.9922, 0.9922, 0.5882, 0.1059, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0627,
0.3647, 0.9882, 0.9922, 0.7333, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.9765, 0.9922, 0.9765, 0.2510, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.1804, 0.5098,
0.7176, 0.9922, 0.9922, 0.8118, 0.0078, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.1529, 0.5804, 0.8980, 0.9922,
0.9922, 0.9922, 0.9804, 0.7137, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0941, 0.4471, 0.8667, 0.9922, 0.9922, 0.9922,
0.9922, 0.7882, 0.3059, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0902, 0.2588, 0.8353, 0.9922, 0.9922, 0.9922, 0.9922, 0.7765,
0.3176, 0.0078, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0706, 0.6706,
0.8588, 0.9922, 0.9922, 0.9922, 0.9922, 0.7647, 0.3137, 0.0353,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.2157, 0.6745, 0.8863, 0.9922,
0.9922, 0.9922, 0.9922, 0.9569, 0.5216, 0.0431, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.5333, 0.9922, 0.9922, 0.9922,
0.8314, 0.5294, 0.5176, 0.0627, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000]]]),
5)
We create a DataLoader object with the specified batch size and shuffle the data randomly before each epoch.
Now, we can define the encoder and decoder networks for the VAE:
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
# Define the layers of the encoder network
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1)
self.fc_mu = nn.Linear(128*7*7, latent_dim)
self.fc_logvar = nn.Linear(128*7*7, latent_dim)
# Define the activation functions
self.relu = nn.ReLU()
def forward(self, x):
# Encode the input image into a latent space representation
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
x = x.view(-1, 128*7*7)
mu = self.fc_mu(x)
logvar = self.fc_logvar(x)
return mu, logvar
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
# Define the layers of the decoder network
self.fc1 = nn.Linear(latent_dim, 128*7*7)
self.deconv1 = nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1)
self.deconv2 = nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1)
self.deconv3 = nn.ConvTranspose2d(32, 1, kernel_size=3, stride=1, padding=1)
# Define the activation functions
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, z):
# Decode the latent space representation into an output image
z = self.relu(self.fc1(z))
z = z.view(-1, 128, 7, 7)
z = self.relu(self.deconv1(z))
z = self.relu(self.deconv2(z))
z = self.sigmoid(self.deconv3(z))
return z
These networks define the encoder and decoder for the VAE. The encoder consists of three convolutional layers and two fully connected layers that output the mean and variance vectors for the Gaussian distribution over the latent space. The decoder consists of three transpose convolutional layers to map the latent space back to the original input space.
We also need to define the loss function for the VAE:
def vae_loss(x, x_hat, mu, logvar):
# Compute the reconstruction error
reconstruction_error = nn.functional.binary_cross_entropy(x_hat, x, reduction='sum')
# Compute the KL divergence between the learned distribution and a unit Gaussian
kl_divergence = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
# print(f'reconstruction_error={reconstruction_error}, kl_divergence={kl_divergence}')
# Sum the two terms to form the overall VAE loss
vae_loss = reconstruction_error + kl_divergence
return vae_loss
This loss function computes the reconstruction error between the generated and original images as well as the KL divergence between the learned distribution and a unit Gaussian. The two terms are combined to form the overall VAE loss.
Here, we define device so we can use GPU for training.
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
device
device(type='cuda', index=0)
Finally, we can train the VAE:
# Instantiate the encoder and decoder networks
encoder = Encoder().to(device)
decoder = Decoder().to(device)
# Set up the optimizer for the VAE
optimizer = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()), lr=learning_rate)
train_losses = []
# Train the VAE
for epoch in range(num_epochs):
for i, (x, _) in enumerate(train_loader):
x = x.to(device)
x = Variable(x)
# Zero out the gradients
optimizer.zero_grad()
# Forward pass through the encoder and decoder networks
mu, logvar = encoder(x)
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
z = eps*std + mu
reconstruct_x = decoder(z)
# Compute the VAE loss and backpropagate the gradients
loss = vae_loss(x, reconstruct_x, mu, logvar)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
# Print the loss every 50 batches
if (i+1) % 50 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Batch [{i+1}/{len(train_loader)}], Loss: {loss.data.item():.4f}')
Epoch [1/30], Batch [50/469], Loss: 27247.3691
Epoch [1/30], Batch [100/469], Loss: 23642.5605
Epoch [1/30], Batch [150/469], Loss: 18193.8516
Epoch [1/30], Batch [200/469], Loss: 17519.3633
Epoch [1/30], Batch [250/469], Loss: 15754.7383
Epoch [1/30], Batch [300/469], Loss: 15262.3604
Epoch [1/30], Batch [350/469], Loss: 14572.5986
Epoch [1/30], Batch [400/469], Loss: 14647.3242
Epoch [1/30], Batch [450/469], Loss: 14704.0020
Epoch [2/30], Batch [50/469], Loss: 13818.4023
Epoch [2/30], Batch [100/469], Loss: 14077.6621
Epoch [2/30], Batch [150/469], Loss: 13600.1660
Epoch [2/30], Batch [200/469], Loss: 13979.6504
Epoch [2/30], Batch [250/469], Loss: 13758.4766
Epoch [2/30], Batch [300/469], Loss: 13828.6445
Epoch [2/30], Batch [350/469], Loss: 13518.7188
Epoch [2/30], Batch [400/469], Loss: 13339.9434
Epoch [2/30], Batch [450/469], Loss: 13390.1553
Epoch [3/30], Batch [50/469], Loss: 14278.5410
Epoch [3/30], Batch [100/469], Loss: 13583.0781
Epoch [3/30], Batch [150/469], Loss: 13713.3262
Epoch [3/30], Batch [200/469], Loss: 13492.0684
Epoch [3/30], Batch [250/469], Loss: 13632.9229
Epoch [3/30], Batch [300/469], Loss: 13346.4043
Epoch [3/30], Batch [350/469], Loss: 13491.8408
Epoch [3/30], Batch [400/469], Loss: 13626.6426
Epoch [3/30], Batch [450/469], Loss: 13180.7529
Epoch [4/30], Batch [50/469], Loss: 13590.8252
Epoch [4/30], Batch [100/469], Loss: 13010.1973
Epoch [4/30], Batch [150/469], Loss: 12699.2207
Epoch [4/30], Batch [200/469], Loss: 12713.8223
Epoch [4/30], Batch [250/469], Loss: 13144.3555
Epoch [4/30], Batch [300/469], Loss: 12867.6582
Epoch [4/30], Batch [350/469], Loss: 12935.9209
Epoch [4/30], Batch [400/469], Loss: 12786.6396
Epoch [4/30], Batch [450/469], Loss: 13215.6885
Epoch [5/30], Batch [50/469], Loss: 13108.1729
Epoch [5/30], Batch [100/469], Loss: 13155.7744
Epoch [5/30], Batch [150/469], Loss: 12610.9531
Epoch [5/30], Batch [200/469], Loss: 12983.3438
Epoch [5/30], Batch [250/469], Loss: 13266.3965
Epoch [5/30], Batch [300/469], Loss: 12714.7979
Epoch [5/30], Batch [350/469], Loss: 12681.2598
Epoch [5/30], Batch [400/469], Loss: 13227.7178
Epoch [5/30], Batch [450/469], Loss: 13220.7236
Epoch [6/30], Batch [50/469], Loss: 12766.7021
Epoch [6/30], Batch [100/469], Loss: 12953.7969
Epoch [6/30], Batch [150/469], Loss: 13306.9395
Epoch [6/30], Batch [200/469], Loss: 12651.4736
Epoch [6/30], Batch [250/469], Loss: 13147.3418
Epoch [6/30], Batch [300/469], Loss: 13231.4199
Epoch [6/30], Batch [350/469], Loss: 12962.5361
Epoch [6/30], Batch [400/469], Loss: 13417.0918
Epoch [6/30], Batch [450/469], Loss: 12108.4111
Epoch [7/30], Batch [50/469], Loss: 12818.8770
Epoch [7/30], Batch [100/469], Loss: 12727.0605
Epoch [7/30], Batch [150/469], Loss: 12885.8008
Epoch [7/30], Batch [200/469], Loss: 12950.7441
Epoch [7/30], Batch [250/469], Loss: 12935.9639
Epoch [7/30], Batch [300/469], Loss: 12944.3945
Epoch [7/30], Batch [350/469], Loss: 12703.4395
Epoch [7/30], Batch [400/469], Loss: 13128.0225
Epoch [7/30], Batch [450/469], Loss: 13321.0664
Epoch [8/30], Batch [50/469], Loss: 12884.9043
Epoch [8/30], Batch [100/469], Loss: 12557.7119
Epoch [8/30], Batch [150/469], Loss: 12965.5479
Epoch [8/30], Batch [200/469], Loss: 12702.5781
Epoch [8/30], Batch [250/469], Loss: 12959.8965
Epoch [8/30], Batch [300/469], Loss: 12888.4111
Epoch [8/30], Batch [350/469], Loss: 12502.4551
Epoch [8/30], Batch [400/469], Loss: 13200.7793
Epoch [8/30], Batch [450/469], Loss: 12644.6758
Epoch [9/30], Batch [50/469], Loss: 12805.0518
Epoch [9/30], Batch [100/469], Loss: 13009.0898
Epoch [9/30], Batch [150/469], Loss: 13087.7793
Epoch [9/30], Batch [200/469], Loss: 12555.0869
Epoch [9/30], Batch [250/469], Loss: 12266.5938
Epoch [9/30], Batch [300/469], Loss: 12307.7695
Epoch [9/30], Batch [350/469], Loss: 13002.4395
Epoch [9/30], Batch [400/469], Loss: 12713.3799
Epoch [9/30], Batch [450/469], Loss: 12528.4453
Epoch [10/30], Batch [50/469], Loss: 12779.4863
Epoch [10/30], Batch [100/469], Loss: 13053.6777
Epoch [10/30], Batch [150/469], Loss: 12707.3770
Epoch [10/30], Batch [200/469], Loss: 12915.2793
Epoch [10/30], Batch [250/469], Loss: 12602.6279
Epoch [10/30], Batch [300/469], Loss: 12130.4961
Epoch [10/30], Batch [350/469], Loss: 12522.1367
Epoch [10/30], Batch [400/469], Loss: 12687.5000
Epoch [10/30], Batch [450/469], Loss: 13169.2998
Epoch [11/30], Batch [50/469], Loss: 12402.4971
Epoch [11/30], Batch [100/469], Loss: 12364.4180
Epoch [11/30], Batch [150/469], Loss: 12521.9766
Epoch [11/30], Batch [200/469], Loss: 12325.0605
Epoch [11/30], Batch [250/469], Loss: 12603.1553
Epoch [11/30], Batch [300/469], Loss: 12702.0537
Epoch [11/30], Batch [350/469], Loss: 12703.6963
Epoch [11/30], Batch [400/469], Loss: 12525.8086
Epoch [11/30], Batch [450/469], Loss: 12963.4990
Epoch [12/30], Batch [50/469], Loss: 12937.9697
Epoch [12/30], Batch [100/469], Loss: 12386.4111
Epoch [12/30], Batch [150/469], Loss: 12758.7617
Epoch [12/30], Batch [200/469], Loss: 12484.9775
Epoch [12/30], Batch [250/469], Loss: 12860.8320
Epoch [12/30], Batch [300/469], Loss: 12672.3037
Epoch [12/30], Batch [350/469], Loss: 12304.7148
Epoch [12/30], Batch [400/469], Loss: 13005.3086
Epoch [12/30], Batch [450/469], Loss: 12477.9902
Epoch [13/30], Batch [50/469], Loss: 12721.9590
Epoch [13/30], Batch [100/469], Loss: 12498.3828
Epoch [13/30], Batch [150/469], Loss: 12451.4463
Epoch [13/30], Batch [200/469], Loss: 12517.6025
Epoch [13/30], Batch [250/469], Loss: 12572.6074
Epoch [13/30], Batch [300/469], Loss: 12268.0537
Epoch [13/30], Batch [350/469], Loss: 12660.3486
Epoch [13/30], Batch [400/469], Loss: 12530.9062
Epoch [13/30], Batch [450/469], Loss: 12446.4717
Epoch [14/30], Batch [50/469], Loss: 12561.6914
Epoch [14/30], Batch [100/469], Loss: 13346.2979
Epoch [14/30], Batch [150/469], Loss: 12754.0918
Epoch [14/30], Batch [200/469], Loss: 12739.1133
Epoch [14/30], Batch [250/469], Loss: 12216.0137
Epoch [14/30], Batch [300/469], Loss: 12949.5469
Epoch [14/30], Batch [350/469], Loss: 13837.9424
Epoch [14/30], Batch [400/469], Loss: 12343.4004
Epoch [14/30], Batch [450/469], Loss: 12298.0049
Epoch [15/30], Batch [50/469], Loss: 12652.0967
Epoch [15/30], Batch [100/469], Loss: 12303.4219
Epoch [15/30], Batch [150/469], Loss: 12720.3613
Epoch [15/30], Batch [200/469], Loss: 12612.0430
Epoch [15/30], Batch [250/469], Loss: 12469.0205
Epoch [15/30], Batch [300/469], Loss: 12084.8906
Epoch [15/30], Batch [350/469], Loss: 11829.7324
Epoch [15/30], Batch [400/469], Loss: 12878.8516
Epoch [15/30], Batch [450/469], Loss: 12916.4922
Epoch [16/30], Batch [50/469], Loss: 11696.0820
Epoch [16/30], Batch [100/469], Loss: 12395.4229
Epoch [16/30], Batch [150/469], Loss: 12689.6680
Epoch [16/30], Batch [200/469], Loss: 12251.7168
Epoch [16/30], Batch [250/469], Loss: 12539.9551
Epoch [16/30], Batch [300/469], Loss: 12798.1270
Epoch [16/30], Batch [350/469], Loss: 12146.0830
Epoch [16/30], Batch [400/469], Loss: 12372.1289
Epoch [16/30], Batch [450/469], Loss: 12793.8438
Epoch [17/30], Batch [50/469], Loss: 12065.4678
Epoch [17/30], Batch [100/469], Loss: 12675.5264
Epoch [17/30], Batch [150/469], Loss: 12177.5205
Epoch [17/30], Batch [200/469], Loss: 12368.5801
Epoch [17/30], Batch [250/469], Loss: 12107.2188
Epoch [17/30], Batch [300/469], Loss: 12525.3613
Epoch [17/30], Batch [350/469], Loss: 12244.9824
Epoch [17/30], Batch [400/469], Loss: 12055.8770
Epoch [17/30], Batch [450/469], Loss: 12435.2891
Epoch [18/30], Batch [50/469], Loss: 12808.9707
Epoch [18/30], Batch [100/469], Loss: 12522.2627
Epoch [18/30], Batch [150/469], Loss: 12156.9893
Epoch [18/30], Batch [200/469], Loss: 12912.7441
Epoch [18/30], Batch [250/469], Loss: 12753.3008
Epoch [18/30], Batch [300/469], Loss: 12472.9766
Epoch [18/30], Batch [350/469], Loss: 12239.3477
Epoch [18/30], Batch [400/469], Loss: 12976.9600
Epoch [18/30], Batch [450/469], Loss: 12499.5508
Epoch [19/30], Batch [50/469], Loss: 12238.7949
Epoch [19/30], Batch [100/469], Loss: 12457.2793
Epoch [19/30], Batch [150/469], Loss: 12352.5059
Epoch [19/30], Batch [200/469], Loss: 12353.5557
Epoch [19/30], Batch [250/469], Loss: 12723.3770
Epoch [19/30], Batch [300/469], Loss: 12085.6484
Epoch [19/30], Batch [350/469], Loss: 12644.1416
Epoch [19/30], Batch [400/469], Loss: 12556.9824
Epoch [19/30], Batch [450/469], Loss: 12454.1885
Epoch [20/30], Batch [50/469], Loss: 12254.3418
Epoch [20/30], Batch [100/469], Loss: 12309.1787
Epoch [20/30], Batch [150/469], Loss: 11857.7949
Epoch [20/30], Batch [200/469], Loss: 12471.7363
Epoch [20/30], Batch [250/469], Loss: 12512.2988
Epoch [20/30], Batch [300/469], Loss: 12298.7246
Epoch [20/30], Batch [350/469], Loss: 12405.1621
Epoch [20/30], Batch [400/469], Loss: 12357.0312
Epoch [20/30], Batch [450/469], Loss: 12473.6318
Epoch [21/30], Batch [50/469], Loss: 12591.0596
Epoch [21/30], Batch [100/469], Loss: 12716.9453
Epoch [21/30], Batch [150/469], Loss: 12610.1465
Epoch [21/30], Batch [200/469], Loss: 12265.8008
Epoch [21/30], Batch [250/469], Loss: 12393.1875
Epoch [21/30], Batch [300/469], Loss: 11962.0234
Epoch [21/30], Batch [350/469], Loss: 12505.2812
Epoch [21/30], Batch [400/469], Loss: 11794.5703
Epoch [21/30], Batch [450/469], Loss: 12180.1562
Epoch [22/30], Batch [50/469], Loss: 12404.6445
Epoch [22/30], Batch [100/469], Loss: 12334.4609
Epoch [22/30], Batch [150/469], Loss: 12556.1836
Epoch [22/30], Batch [200/469], Loss: 12641.7012
Epoch [22/30], Batch [250/469], Loss: 12578.8135
Epoch [22/30], Batch [300/469], Loss: 12246.1953
Epoch [22/30], Batch [350/469], Loss: 12587.1689
Epoch [22/30], Batch [400/469], Loss: 12538.3721
Epoch [22/30], Batch [450/469], Loss: 12227.1748
Epoch [23/30], Batch [50/469], Loss: 12283.7461
Epoch [23/30], Batch [100/469], Loss: 12275.3789
Epoch [23/30], Batch [150/469], Loss: 12311.4326
Epoch [23/30], Batch [200/469], Loss: 12426.3232
Epoch [23/30], Batch [250/469], Loss: 12835.8750
Epoch [23/30], Batch [300/469], Loss: 12625.6982
Epoch [23/30], Batch [350/469], Loss: 12421.7578
Epoch [23/30], Batch [400/469], Loss: 12465.7617
Epoch [23/30], Batch [450/469], Loss: 12988.3750
Epoch [24/30], Batch [50/469], Loss: 12371.3213
Epoch [24/30], Batch [100/469], Loss: 12573.0430
Epoch [24/30], Batch [150/469], Loss: 12453.7285
Epoch [24/30], Batch [200/469], Loss: 12106.1514
Epoch [24/30], Batch [250/469], Loss: 12107.3633
Epoch [24/30], Batch [300/469], Loss: 12357.3945
Epoch [24/30], Batch [350/469], Loss: 12204.4902
Epoch [24/30], Batch [400/469], Loss: 12419.8574
Epoch [24/30], Batch [450/469], Loss: 12182.1396
Epoch [25/30], Batch [50/469], Loss: 12790.7578
Epoch [25/30], Batch [100/469], Loss: 12528.9170
Epoch [25/30], Batch [150/469], Loss: 12084.2510
Epoch [25/30], Batch [200/469], Loss: 12126.9756
Epoch [25/30], Batch [250/469], Loss: 12233.0430
Epoch [25/30], Batch [300/469], Loss: 12342.8535
Epoch [25/30], Batch [350/469], Loss: 12105.4805
Epoch [25/30], Batch [400/469], Loss: 12978.1299
Epoch [25/30], Batch [450/469], Loss: 12168.1006
Epoch [26/30], Batch [50/469], Loss: 12502.1074
Epoch [26/30], Batch [100/469], Loss: 11961.0137
Epoch [26/30], Batch [150/469], Loss: 11979.2080
Epoch [26/30], Batch [200/469], Loss: 12410.2285
Epoch [26/30], Batch [250/469], Loss: 12663.5117
Epoch [26/30], Batch [300/469], Loss: 12355.5459
Epoch [26/30], Batch [350/469], Loss: 12390.4355
Epoch [26/30], Batch [400/469], Loss: 12211.8232
Epoch [26/30], Batch [450/469], Loss: 11939.8535
Epoch [27/30], Batch [50/469], Loss: 12165.7656
Epoch [27/30], Batch [100/469], Loss: 12779.2559
Epoch [27/30], Batch [150/469], Loss: 12499.7002
Epoch [27/30], Batch [200/469], Loss: 12743.3623
Epoch [27/30], Batch [250/469], Loss: 12497.2812
Epoch [27/30], Batch [300/469], Loss: 12391.8936
Epoch [27/30], Batch [350/469], Loss: 12483.7637
Epoch [27/30], Batch [400/469], Loss: 12383.3633
Epoch [27/30], Batch [450/469], Loss: 12780.3086
Epoch [28/30], Batch [50/469], Loss: 12376.0664
Epoch [28/30], Batch [100/469], Loss: 12019.8213
Epoch [28/30], Batch [150/469], Loss: 12155.3643
Epoch [28/30], Batch [200/469], Loss: 12244.5703
Epoch [28/30], Batch [250/469], Loss: 12176.7520
Epoch [28/30], Batch [300/469], Loss: 12013.6602
Epoch [28/30], Batch [350/469], Loss: 12439.5039
Epoch [28/30], Batch [400/469], Loss: 11771.2637
Epoch [28/30], Batch [450/469], Loss: 11946.9043
Epoch [29/30], Batch [50/469], Loss: 11932.0010
Epoch [29/30], Batch [100/469], Loss: 11980.0938
Epoch [29/30], Batch [150/469], Loss: 11985.5664
Epoch [29/30], Batch [200/469], Loss: 12358.0771
Epoch [29/30], Batch [250/469], Loss: 12459.0654
Epoch [29/30], Batch [300/469], Loss: 12180.4805
Epoch [29/30], Batch [350/469], Loss: 12235.3525
Epoch [29/30], Batch [400/469], Loss: 12438.6982
Epoch [29/30], Batch [450/469], Loss: 12068.7529
Epoch [30/30], Batch [50/469], Loss: 12111.2656
Epoch [30/30], Batch [100/469], Loss: 12615.3750
Epoch [30/30], Batch [150/469], Loss: 11945.4385
Epoch [30/30], Batch [200/469], Loss: 12439.0439
Epoch [30/30], Batch [250/469], Loss: 12417.5059
Epoch [30/30], Batch [300/469], Loss: 12433.4658
Epoch [30/30], Batch [350/469], Loss: 12037.2148
Epoch [30/30], Batch [400/469], Loss: 12366.6377
Epoch [30/30], Batch [450/469], Loss: 12381.0693
This code trains the VAE on the MNIST dataset using the specified hyperparameters. We forward pass the input data through the encoder and decoder networks, compute the VAE loss, and backpropagate the gradients to update the weights of the networks. We also print the loss every 50 batches. After training is complete, we can generate some samples from the learned distribution:
plt.plot(train_losses)
plt.show()
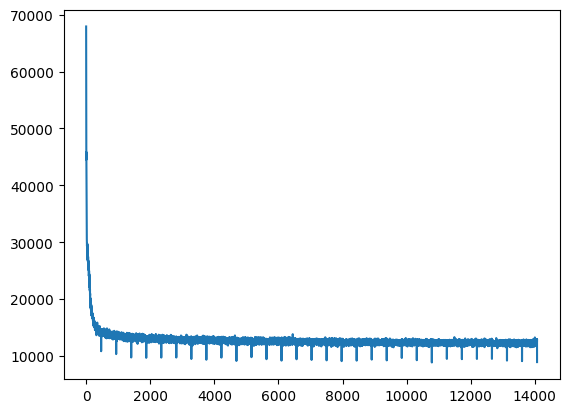
with torch.no_grad():
z = torch.randn(num_samples, latent_dim).to(device)
samples = decoder(z)
We sample num_samples vectors from a Gaussian distribution over the latent space and use the decoder network to decode them back into the original input space.
Then, we can visualize the generated samples. This code displays num_samples generated images in a grid:
fig, axes = plt.subplots(nrows=4, ncols=4, figsize=(8, 8))
samples = torch.Tensor.cpu(samples)
for i, ax in enumerate(axes.flatten()):
ax.imshow(samples[i].view(28, 28), cmap='gray')
ax.axis('off')
plt.show()

These are some generates samples using the decoder part of VAE. As you can see they almost look like MNIST numbers. Therefore, that is how we can use VAE to generate new samples like our dataset.